 @pgate1
@pgate1
投稿日 2019年5月26日 更新日 2023年5月13日
USB-Blaster 経由で FPGA とデータ送受信したい!
USB-Blaster 経由でPC側の自作ソフトとFPGA間のデータ送受信を活用しましょう、という話です。対象FPGAボード
USB-Blaster 回路が載っているTerasic社製のDE0、DE1、DE2-115、DE0-CV等になります (あとおそらくDE0-Nano、DE10-Liteも)。 また、Terasic USB Blaster Download Cable でも使用できるため、Analogue Pocket等でも使用できます (残念ながら1chipMSXはJTAGピンが未結線のため使用できませんでした)。 なお、USB-BlasterII については調査中です。従来のデータ送受信
DE1のFPGAにPCのユーザプログラムからデータを流し込むために、 最初はRS-232経由でUARTを使っていました。 しかし標準的な230,400baudで実効速度が約20kB/sしか出ず、 ケーブルの取り回しも面倒でした。 さらにDE0でUARTするためにはRS-232コネクタを増設する必要があります。 そしてある程度の転送サイズと転送速度も欲しい。 FPGAにFAT16を実装して2GBのノーマルSDカード経由という手もやりましたが、やっぱりデータの差し替えが面倒です。 ちなみに USB-Blaster はドライバ設定で VCP(Virtual COM Port)としても使えますが、 実効速度としては約60kB/sくらいでした。VirtualJTAG と D2XX を使う
そこで、VirtualJTAG を使ってデータ送受信する方法を探っていました。 具体的な方法はかず氏がまとめていらっしゃいます [Terasic DE0ボードでのUSB通信②]。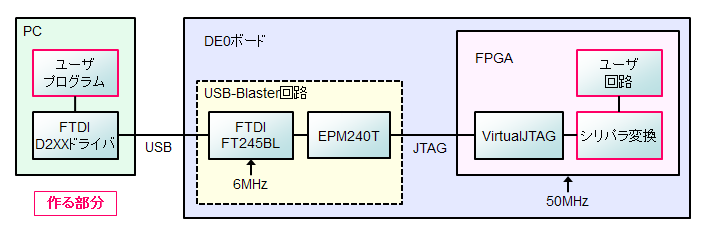 今回対象としている USB-Blaster 回路には FTDI のチップが使用されていて、
FTDI の D2XXドライバを自作プログラムで使用すればFPGAとUSB経由で繋がります。
さらにFPGA内の VirtualJTAG の回路を使うようにHDLでインスタンスすれば、
JTAGのコマンドを使ってJTAGレジスタを操作できます。
このJTAGレジスタとユーザ回路を接続して、ユーザプログラムとUSB経由でデータを送受信するわけです。
今回対象としている USB-Blaster 回路には FTDI のチップが使用されていて、
FTDI の D2XXドライバを自作プログラムで使用すればFPGAとUSB経由で繋がります。
さらにFPGA内の VirtualJTAG の回路を使うようにHDLでインスタンスすれば、
JTAGのコマンドを使ってJTAGレジスタを操作できます。
このJTAGレジスタとユーザ回路を接続して、ユーザプログラムとUSB経由でデータを送受信するわけです。
今のところ、FPGAへのデータ送信速度は約610kB/s、 PCへのデータ受信速度は約380kB/sとなっています。 DE0,D0-CV向けのFPGAデータと送受信のためのC++コードを置いておきます。
Virtual JTAG
Virtusl JTAG IP は、QuartusII MegaWizard もしくは QuartusPrime IP Catalog で生成します。 ir(instruction register)ビット幅を8bitにして、あとはデフォルトでかまいません。参考:仮想JTAG(altera_virtual_jtag)IPコアのユーザーガイド (PDF)
FPGA側コード例
VirtualJTAG の使い方等は上記サイトを参考にして頂くとして、 今回は数Mバイト程度のデータをFPGAと送受信するために工夫してみました (DE0-CVで32Mバイトまでの送受信の動作を確認)。 ちなみにFPGAのメインクロックは50MHzです。
vjtag_uart.v
VirtualJTAG vjtag (
.tdo(tdo),
.ir_in(ir_in),
.tck(tck),
.tdi(tdi),
.virtual_state_sdr(virtual_state_sdr),
.virtual_state_uir(virtual_state_uir)
);
localparam COMMAND_RECV = 8'h41;
localparam COMMAND_SEND = 8'h42;
reg t_init, t_recv, t_send;
reg [7:0] ir, dr, ds;
reg [2:0] count;
always @(posedge p_reset or posedge tck) begin
if(p_reset) begin
t_init <= 0;
t_recv <= 0;
t_send <= 0;
end
else if(virtual_state_uir) begin
ir <= ir_in;
t_init <= 1;
end
else if(t_init) begin
count <= 0;
if(ir==COMMAND_SEND) t_send <= 1;
t_init <= 0;
end
else if(virtual_state_sdr) begin
dr[count] <= tdi;
count <= count + 1;
if(count==7) begin
if(ir==COMMAND_RECV) t_recv <= 1;
if(ir==COMMAND_SEND) t_send <= 1;
end
else begin
if(ir==COMMAND_RECV) t_recv <= 0;
if(ir==COMMAND_SEND) t_send <= 0;
end
end
end
以下はFPGA側ユーザ回路、vjtag_test.sflp の一部。 32,768 Byteを内蔵メモリに受信して、次に送信するだけのテストサンプルです。 注意点は、FPGAからの send について、1バイト先読みを行うため vjtag.send_ready が1回多く発生することです。
vjtag_test.sflp
vjtag_uart vjtag;
mem ram[32768]<8>;
reg_wr ram_dout<8>, adrs<15>;
 instruct vjtag.recv_init par{
adrs := 0;
}
instruct vjtag.recv par{
ram[adrs] := vjtag.recv_data;
adrs++;
}
instruct vjtag.send_init par{
adrs := 0;
}
reg_wr vjtag_send;
instruct vjtag.send_ready par{
ram_dout := ram[adrs];
adrs++;
vjtag_send := 0b1;
}
if(vjtag_send){
vjtag.send(ram_dout);
vjtag_send := 0b0;
}
instruct vjtag.recv_init par{
adrs := 0;
}
instruct vjtag.recv par{
ram[adrs] := vjtag.recv_data;
adrs++;
}
instruct vjtag.send_init par{
adrs := 0;
}
reg_wr vjtag_send;
instruct vjtag.send_ready par{
ram_dout := ram[adrs];
adrs++;
vjtag_send := 0b1;
}
if(vjtag_send){
vjtag.send(ram_dout);
vjtag_send := 0b0;
}
D2XXドライバ
FTDI のサイトから D2XX のドライバを取得できます。 ftd2xx.lib と ftd2xx.h を使います。参考:D2XX Programmer's Guide (PDF)
PC側ユーザプログラム例
送信
ポイントは書き込みバッファを FT_Write でまとめて1回で送信すること。 バッファ内で63バイト毎にWriteコマンド(WR)を挿入し、まとめて送信することで実行速度は約610kB/sとなります。
送信プログラム例
int BlasterSend(FT_HANDLE ftHandle, uint8 *send_data, const int send_size)
{
MoveIdle(ftHandle);
MoveIdleToShiftir(ftHandle);
WriteShiftir(ftHandle, 0x0E); // USER1
MoveShiftirToShiftdr(ftHandle);
WriteShiftdr(ftHandle, 0x41); // カウンタリセットのため(FPGA recv)
MoveShiftdrToShiftir(ftHandle);
WriteShiftir(ftHandle, 0x0C); // USER0
MoveShiftirToShiftdr(ftHandle);
// Writeするバイトサイズ
DWORD bytes_to_write = ((send_size - 1) / 63) + send_size + 1;
// バッファサイズは63バイト毎に32ワード
int write_buf_size = (bytes_to_write + 1) / 2;
// 32ワードで割り切れるサイズでwrite_bufを確保する
write_buf_size = ((write_buf_size - 1) / 32 + 1) * 32;
uint16 *write_buf = new uint16[write_buf_size];
int last_index = 0;
for(int i=0, d=0; i<write_buf_size; i+=32, d+=63){
// 32ワード毎にWRを入れる
write_buf[i] = WR | 0x003F; // Write max 63
memcpy((uint8*)(write_buf + i) + 1, send_data + d, 63);
// 最後のWR位置を記憶しておく
last_index = i;
}
// 63でワンセットなので63で割った余りを最後のWR位置に入れる。
uint16 rem = send_size % 63;
if(rem!=0) write_buf[last_index] = (write_buf[last_index] & 0xFF00) | WR | rem;
DWORD bytes_written;
FT_Write(ftHandle, write_buf, bytes_to_write, &bytes_written);
delete[] send_buf;
DeviceClose(ftHandle);
return 0;
}
受信
送信時のバッファ同様に、Readコマンド(RD)あたり最大63バイトを指定したものを準備します。 それを受信サイズ分だけまとめて FT_Write し、次に FT_Read するとデータを受信できます。 これにより受信の実効速度は約380kB/sとなりました。
受信プログラム例
int BlasterRecv(FT_HANDLE ftHandle, uint8 *recv_data, const int recv_size)
{
MoveIdle(ftHandle);
MoveIdleToShiftir(ftHandle);
WriteShiftir(ftHandle, 0x0E); // USER1
MoveShiftirToShiftdr(ftHandle);
WriteShiftdr(ftHandle, 0x42); // カウンタリセットのため(FPGA send)
MoveShiftdrToShiftir(ftHandle);
WriteShiftir(ftHandle, 0x0C); // USER0
MoveShiftirToShiftdr(ftHandle);
DWORD bytes_to_write = ((recv_size - 1) / 63) + recv_size + 1;
// バッファサイズは63バイト毎に32ワード
int write_buf_size = (bytes_to_write + 1) / 2;
uint16 *write_buf = new uint16[write_buf_size];
memset(write_buf, 0x00, write_buf_size * 2);
int last_index = 0;
for(int i=0; i<write_buf_size; i+=32){
// 32ワード毎にRDを入れる
write_buf[i] = RD | 0x003F; // Read max 63
// 最後のRD位置を記憶しておく
last_index = i;
}
// 63でワンセットなので63で割った余りを最後のRD位置に入れる。
uint16 rem = recv_size % 63;
if(rem!=0) write_buf[last_index] = RD | rem;
DWORD bytes_written;
FT_Write(ftHandle, write_buf, bytes_to_write, &bytes_written);
DWORD bytes_read;
FT_Read(ftHandle, recv_data, recv_size, &bytes_read);
delete[] recv_buf;
DeviceClose(ftHandle);
return 0;
}
ただこの受信方法だけでは、受信サイズが256kバイトほどのサイズを超えると、
バッファあふれのせいか速度が40kB/sまで落ちてしまい実用的ではありません。
そこでおおよそ、(4000*63)バイト毎に上記 BlasterRecv 関数を呼ぶ形で速度を落とさずに大きいサイズを受信できるようにしました。
受信プログラム例(大きい受信サイズ対応)
// 受信サイズがRECV_MAXを超える場合に、RECV_MAX毎に受信する。
#define RECV_MAX (4000 * 63)
int BlasterRecv(FT_HANDLE ftHandle, uint8 *recv_data, const int recv_size)
{
MoveIdle(ftHandle);
MoveIdleToShiftir(ftHandle);
WriteShiftir(ftHandle, 0x0E); // USER1
MoveShiftirToShiftdr(ftHandle);
WriteShiftdr(ftHandle, 0x42); // カウンタリセットのため(FPGA send)
MoveShiftdrToShiftir(ftHandle);
WriteShiftir(ftHandle, 0x0C); // USER0
MoveShiftirToShiftdr(ftHandle);
int count = recv_size / RECV_MAX;
for(int i=0; i<count; i++){
BlasterRecv(ftHandle, recv_data + RECV_MAX * i, RECV_MAX, false);
}
BlasterRecv(ftHandle, recv_data + RECV_MAX * count, recv_size % RECV_MAX, false);
DeviceClose(ftHandle);
return 0;
}
サンプルの実行結果
size 32768 byte
send sum 0x4B
send 51ms 627.5 kB/s
recv sum 0x4B
recv 83ms 385.5 kB/s
送受信速度はFPGAボード付属のデモツールより10倍速い結果となりました!
ちなみに、FT_SetBaudRate でボーレートの設定ができるか試しましたが、 使用されているデバイス FT245BL は設定できないようでした。
まとめ
以上のように、USB-Blaster とVirtualJTAG 経由でデータ送受信できるようになりました。 DE0、DE1、DE0-CVボードなら、USBケーブル1本でバスパワー電源と、FPGAコンフィギュレーションと、データ送受信で一挙三得です! データ送信速度は自作FAT16&SDカードコントローラ以上になりました。 使わなくなったRS-232ケーブルとSDカードは窓からポイしましょう。
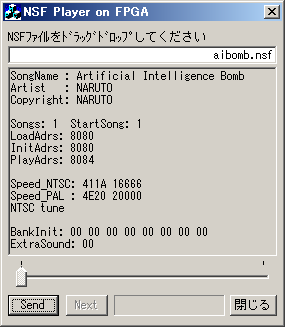
ユーザプログラムの例:
より新しいTerasic社FPGAボードであるDE10-NanoやDE1-SoCなどには、 Cypress のUSBチップを使用した USB-BlasterII 回路が載っています。 USB-Blaster は USB1.1 Full-Speed(12Mbps)接続のFTDIチップ動作クロック6MHzですが、 USB-BlasterII は USB2.0 High-Speed(480Mbps)接続でCypressチップ動作クロックが24MHzのため、 これが使えるようになれば USB-Blaster の3倍程度の実効速度で送受信できるかも?