| NES on FPGA | 2010/10/08 |
dev CPU (6502僇僗僞儉)
|
丂CPU偺幚憰偱偼柦椷偺幚峴僋儘僢僋悢傪崌傢偣偰偄傑偡丅 懡偔偺僎乕儉偱偼VBlank偱僞僀儈儞僌傪偲偭偰偄傞偨傔丄 幚峴僋儘僢僋悢傪崌傢偣傞昁梫偼柍偄傛偆偵巚傢傟偨偺偱偡偑丄 堦晹偺僎乕儉偱偼儔僗僞僗僋儘乕儖傪峴偭偰偄傞傕偺偑偁傞偨傔偱偡丅 丂僆儕僕僫儖偼慡偰偺僋儘僢僋偵偍偄偰儊儌儕傾僋僙僗偑敪惗偟傑偡偑丄 崱偺偲偙傠昁梫側僞僀儈儞僌偺傒偱偺傾僋僙僗偱栤戣側偄傛偆偱偡丅 傑偨巇條奜柦椷傕懚嵼偟傑偡偑丄崱偺偲偙傠摦嶌偟偨僎乕儉偱偼妋擣偱偒傑偣傫丅 偨偩偟丄巇條奜柦椷傪幚憰偡傞偙偲偱夞楬偺嶍尭偑壜擻側傜幚憰偟偨偄偲偙傠偱偡丅 | ! | W65C02S偺愇傗僨乕僞僔乕僩偼丄Western Design Center偐傜擖庤壜擻. |
丵
仴 Ver.1 側偵偼偲傕偁傟
丂偲傝偁偊偢摦偔傕偺傪偲丄慡柦椷偵偍偄偰柦椷僼僃僢僠丄幚峴丄僗僩傾偺奺僗僥乕僕傪偛偪傖傑偤偱婰弎丅
SFL2VHDL偱儊儌儕僆乕僶丄曄姺偱偒偢丅偦傝傖偹丅
偲偄偆偙偲偱丄傾僪儗僢僔儞僌偛偲偵懡彮偺榑棟嵟揔壔傗偭偰傒偰傛偆傗偔曄姺偱偒偨偺偱崌惉丄
僨僼僅儖僩偺柺愊嵟揔壔偱僋儕僥傿僇儖60ns丅33MHz偱摦偄偰梸偟偄偺偱偙傟偼偪傚偭偲抶偄丅
偱丄懍搙嵟揔壔丄廃婜30.303ns偱崌惉
Total equivalent gate count for design: 12,367
丂偓偪偓偪偵嵟揔壔偝傟偨6502偺IP偑摨堦忦審壓偱偺崌惉寢壥偱7,600僎乕僩掱搙偩偭偨偺偱丄 傑偢偼偙傫側傕傫偱偡偐丅愘懍庡媊僶儞僓僀丅
丵
仴 Ver.2 傕偭偲椙偔尒偣偰
丂傕偆彮偟尒塰偊傪椙偔偟傛偆偐偲偄偆偙偲偱丄 傾僪儗僢僔儞僌偲幚峴丄妱傝崬傒傪暿僗僥乕僕偵暘偗傑偟偨丅 僗僋儔僢僠偐傜8帪娫偱姰惉丅
Total equivalent gate count for design: 11,221丂僎乕僩悢偁傫傑傊傜偹偊側偁丅
丂偲偙偙偱僴僀僪儔僀僪僗儁僔儍儖偑搑拞偱僼儕乕僘丅 僾儘僌儔儉僇僂儞僞(PC)偑$0012傪巜偟偰傞丅 PC偼$8000乣偟偐巜偝側偄傕偺偲巚偄崬傒丄 僨僶僢僌偺偨傔PC偑$0000乣$7FFF傪巜偡偲掆巭偡傞傛偆偵偟偰偄偨丅 偳偆傗傜WRAM忋偵僾儘僌儔儉傪彂偄偰偄傞傜偟偔丄 JSR偱$0012傊旘傫偱偨丅
丵
仴 Ver.3 偓偪偓偪
|
丂崻杮揑偵側偵偐愝寁曽朄傪娫堘偭偰傞傛偆側婥偑偟偰側傜側偄丅 偟偐偟偙傟埲忋偺嵟揔壔偼傑偡傑偡婰弎偺尒捠偟偑埆偔側傞偽偐傝丅 夞楬婯柾傪尭傜偡昁梫偑偁傟偽偱偡偑丅 丂傗偼傝撪晹RAM傪巊偭偨儅僀僋儘僐乕僪曽幃偵偟偰丄 傾僪儗僗僨僐乕僟傪側偔偡傋偒偐丠 | ! | 偄偔傜尒傗偡偄傛偆偵偲偼偄偊曄側愝寁丅 |
丵
仴 Ver.4 怴揤抧傊
丂DE1儃乕僪傊偺堏怉偵敽偄丄嵟戝摦嶌廃攇悢傕50MHz偑梫媮偝傟傞丅 榑棟崌惉僣乕儖偼Altera QuartusII 9.0 Web Edition傪巊梡丅 SFL偐傜HDL傊偺曄姺偼丄SFL2VHDL偐傜sfl2vl偵曄峏丅 偙傟偵傛傝夞楬婯柾偼5暘偺3傑偱嶍尭丅 懍搙惈擻傕2妱埲忋傾僢僾偟丄50MHz偼梋桾偱僋儕傾偱偒偨丅 偝傜偵奺墘嶼柦椷傪嶶敪揑側墘嶼巕偱峴偭偰偄偨傕偺傪ALU偵儌僕儏乕儖壔偟偨傝丄 儘僕僢僋偱慻傫偱偄偨壛嶼婍傪墘嶼巕偵曄峏偟偨傝丄 僨乕僞僶僗傪堦晹尒捈偟偨傝偱摦嶌廃攇悢63MHz傑偱崅懍壔丅
丂傑偁僋儘僢僋僪儊僀儞傪暘偗傟偽暿偵5MHz掱搙偱傕偄偄傫偱偡偑丅
丵
仴 墘嶼寢壥
丂奺墘嶼柦椷偵偍偗傞墘嶼寢壥偲僼儔僌偺曄壔偼埲壓偺傛偆偵側偭偰偄傑偡丅
[ADC墘嶼寢壥乮420KByte乯]
[SBC墘嶼寢壥乮390KByte乯]
[CMP墘嶼寢壥乮220KByte乯] CPX丄CPY傕摨條偱偡丅
丵
仴 柦椷僙僢僩埑弅
丂柦椷儅僩儕僋僗傪尒側偑傜柦椷暿偺埑弅傪峴偄傑偟偨丅
[柦椷儅僩儕僋僗乮Excel宍幃乯] 報嶞偟偰巊梡偡傞偲曋棙両
[柦椷僙僢僩埑弅寢壥]
丵
仴 儗僕僗僞傊偺僨乕僞儘乕僪偵偮偄偰
丂尦棃6502偼68宯偵帡偨MPU偱偁傞偨傔儗僕僗僞傊偺僨乕僞偺撉傒崬傒偼丄 偦偺僋儘僢僋撪偱峴傢側偗傟偽側傜偢丄 儊儌儕偑抶偄偲MPU偺僋儘僢僋廃攇悢傪棊偲偡昁梫偑偁傝傑偟偨丅 崱夞偼33MHz傪儀乕僗僋儘僢僋偲偟偰偄傞偺偱丄 80宯偺CPU偵尒傜傟傞傛偆側儗僨傿擖椡傪梡堄偟丄 偙偄偮偵儊儌儕偐傜ACK傪曉偡偙偲偱儗僕僗僞傊偺僨乕僞撉傒崬傒傪峴偆傛偆偵偟偰偄傑偡丅
丂偪側傒偵6502偵偼RDY擖椡偑偁傝傑偡偑丄 偙偺RDY擖椡偼扨偵摦嶌傪掆巭偝偣傞偨傔偺傕偺偱偁傞偨傔丄 儗僕僗僞偲偼娭學偁傝傑偣傫丅
丵
仴 僨僶僢僌夞楬
丂榑棟愝寁僄儔乕傕偩偑丄FPGA奜晹偺暔棟揑側僄儔乕偲偼栵夘側傕偺偱丄
偄偭偨傫偙偄偮偵偗偮傑偢偔偲悢帪娫傪柍懯偵偟偐偹側偄丅
偦偙偱柦椷儗僕僗僞偵憐掕奜偺柦椷偑儘乕僪偝傟偨応崌偼
CPU傪掆巭偝偣傞傛偆側夞楬傪偮偗偰偍偔偲曋棙丅
捠忢偼僗僀僢僠傪愗偭偰偍偗偽傛偄丅
[憐掕奜柦椷僙僢僩埑弅寢壥]
丵
仴 僥僉僗僩斾妑偵傛傞専徹曽朄 2008/10/17
丂FPGA忋偱Dr.儅儕僆傗DQ3偺僞僀僩儖夋柺偑昞帵偝傟側偐偭偨丅 僄儈儏偱偼偪傖傫偲摦嶌偟偰偄傞偺偱丄SFL傪sfl2vl偱verilog偵曄姺偟丄 verilator偵偰幚峴偟儘僌傪庢摼丄僄儈儏偺摦嶌儘僌偲斾妑偡傞偙偲偱尨場傪摿掕偡傞丅
丂偙偺傛偆側CPU偺儘僌斾妑偼僥僉僗僩儀乕僗偱峴偆偲曋棙偩丅
僄儈儏偐傜偼攇宍傛傝僥僉僗僩偑娙扨偵庢傟傞偟丄
HDL懁偱攇宍傪庢摼偡傞偨傔偵偼僥僗僩儀儞僠嶌惉偑柺搢偩偟丅
僥僉僗僩斾妑僣乕儖偼偁偄傑偄斾妑傕偱偒傞偺偱僆僗僗儊偱偁傞丅
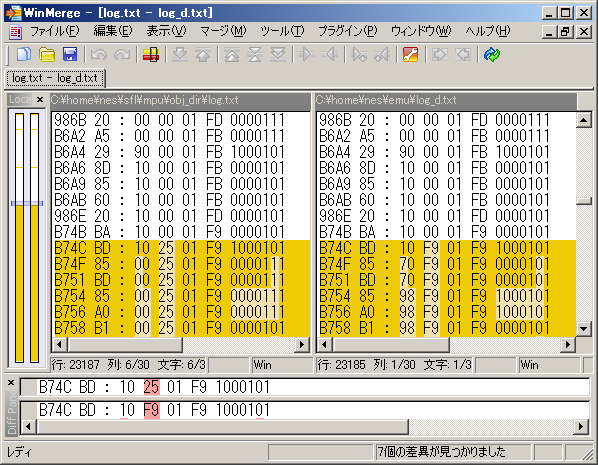
WinMerge偵傛傞僥僉僗僩儘僌斾妑
丂僞僀僩儖夋柺昞帵偁偨傝傑偱50000柦椷幚峴屻偐傜30000柦椷偺儘僌傪庢摼丅
73187柦椷幚峴屻乮摨堦柦椷偺楢懕幚峴偼彍奜乯偺TSX($BA)偵偰X儗僕僗僞偵擖傞抣偑堎側偭偰偄偨丅
丂僄儈儏偲SFL偺僐乕僪傪斾妑偟偨偲偙傠丄僄儈儏偱偼惓偟偔
丂r_x = r_stack;
偲丄僗僞僢僋偺抣傪僗僩傾偟偰偄傞偑丄
SFL偱偼
丂rx := pstate;
偲丄岆偭偰僼儔僌僗僥乕僞僗傪僗僩傾偡傞婰弎偵側偭偰偟傑偭偰偄偨丅
丂偙傟傪廋惓偟丄FPGA忋偱傕栤戣側偔僞僀僩儖夋柺偑昞帵偝傟偨丅
丂側偍丄7827丄16337丄66669丄109339柦椷幚峴帪偵VBlank偑丄 24987丄44252丄53763丄63445丄72858柦椷幚峴帪偵NMI偑敪惗偡傞偨傔丄 SFL懁偱傕偦傟傜傪媅帡揑偵敪惗偝偣偰偄傞丅 偦傟傜敪惗僞僀儈儞僌偱偺儘僌偺堘偄偑丄 73187柦椷慜傑偱偺嵎暘偲偟偰尰傟偰偄傞丅
丵
仴 僋儘僢僋悢傪崌傢偣傛 2008/10/20
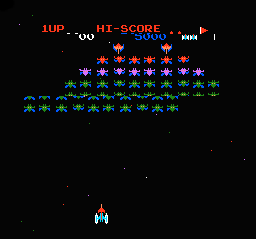
揋僉儍儔偑偢傟偢傟
丂僊儍儔僋僔傾儞偺摦嶌妋擣偱丄杮棃側傜揋僉儍儔慡懱偑墶偵僗僋儘乕儖偡傋偒偲偙傠偱丄 偢傟偢傟偩偭偨乮Y嵗昗35偲97晅嬤乯丅 偙傟偼丄X僗僋儘乕儖儗僕僗僞傊偺write僞僀儈儞僌偑栤戣偩偲峫偊傜傟偨偨傔丄 偦偺晅嬤偺柦椷傪拪弌偟偨偲偙傠師偺傛偆側傕偺偩偭偨丅
| 僋儘僢僋悢 | |||
| adrs 柦椷 | opcode | Emu | 岆HDL |
| E288 DEC | C6 E0 | 丂5 | 丂4 |
| E28A DEC | C6 E0 | 丂5 | 丂4 |
| E28C DEC | C6 E0 | 丂5 | 丂4 |
| E28E DEY | 88 | 丂2 | 丂2 |
| E28F BEQ | F0 03 | 丂2 | 丂2 |
| E291 JMP | 4C 88 E2 | 丂3 | 丂3 |
丂偙傟傪尒傞偲丄儔僀儞40晅嬤傑偱DEC柦椷偱僇僂儞僩偟丄 0偵側偭偨傜X僗僋儘乕儖儗僕僗僞傪彂偒姺偊偰偄傞傛偆偩偭偨丅 拲栚偡傋偒偼DEC柦椷偺幚峴僋儘僢僋悢偑僄儈儏偲HDL偱堎側偭偰偄偨偙偲丅 杮棃側傜5僋儘僢僋梫偡傞偲偙傠傪4僋儘僢僋偱幚峴偟偰偄偨偨傔丄 梊掕傛傝傕憗偔X儗僕僗僞傊偺write偑峴傢傟偰偟傑偭偰偄偨傛偆偩丅
丂HDL傪廋惓偟丄5僋儘僢僋偱幚峴偡傞傛偆偵偟偨偲偙傠丄 婜懸捠傝揋僉儍儔偺傒墶偵僗僋儘乕儖偡傞傛偆偵側偭偨丅 懠偺柦椷偱傕僋儘僢僋悢傪尩枾偵巇條偲崌傢偣偨丅 僋儘僢僋悢傪峫偊偰僾儘僌儔儉偝傟偰偄傞僎乕儉偑懠偵傕偁傝偦偆偩丅
丵
仴 柦椷僷僀僾儔僀儞偼側偄両 2010/10/05
丂乽6502偼僷僀僾儔僀儞婡峔傪帩偭偰偄傞乿
側偳偲嶨帍傗Wiki側偳偱彂偐傟偰偄傞偙偲偑偁傞偑丄偙傟偵偼媈栤偑偁偭偰挷傋偰傒偨丅
寢榑偐傜尵偆偲丄
6502偼僗僩乕儖懳嶔傗僼僅儚乕僨傿儞僌側偳偺傛偆側杮奿揑側柦椷僷僀僾儔僀儞偼幚憰偝傟偰偄側偄偙偲偑暘偐偭偨丅
幚嵺偵偼丄墘嶼柦椷側偳堦晹偺柦椷偱丄嵟屻偺僋儘僢僋偱儊儌儕傾僋僙僗偟側偄応崌丄
墘嶼偲師偺柦椷僼僃僢僠傪僆乕僶乕儔僢僾偡傞偙偲偱1僋儘僢僋抁弅偡傞丅
偙傟傪僷僀僾儔僀儞偩偲尵偆恖偼尵偆丄偲偺偙偲偺傛偆偩丅
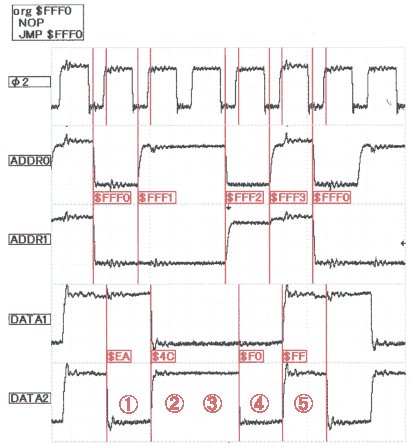
NOP & JMP loop 偺攇宍
丂偦偙偱塃偺攇宍傪尒偰偄偨偩偙偆丅
偙傟偼丄NOP($EA)偲JMP($4C)偱儖乕僾偟偰偄傞僼傽儈僐儞偺攇宍傪朸巵偐傜擖庤偟偨傕偺偩偑丄
堦尒丄NOP偺師偺JMP柦椷傪僆乕僶乕儔僢僾偱愭峴僼僃僢僠偟偰偄傞傛偆偵尒偊傞丅
偟偐偟僨乕僞僔乕僩偱偼NOP偼2僋儘僢僋丄JMP偼3僋儘僢僋偱偁傝丄
愭峴僼僃僢僠偵傛傞僋儘僢僋抁弅偼娤應偝傟側偄丅
丂偙傟偼柦椷僼僃僢僠偺屻偵昁偢戞堦僆儁儔儞僪偑僼僃僢僠偝傟傞巇條偵傛傞傕偺偱丄
丂嘆 NOP柦椷傪僼僃僢僠
丂嘇 NOP幚峴乮壗傕偟側偄乯仌 師偺傾僪儗僗傪僼僃僢僠
丂嘊 JMP柦椷傪僼僃僢僠
丂嘋 壓埵傾僪儗僗傪僼僃僢僠
丂嘍 忋埵傾僪儗僗傪僼僃僢僠
偲偄偆偙偲偑暘偐傞丅
丂嘇偱師偺JMP柦椷傪愭峴僼僃僢僠偟偰偄傞傛偆偵尒偊傞偑丄
悇應偝傟傞傋偒偼偙傟偼data儗僕僗僞傊偺僼僃僢僠偱丄
instruction儗僕僗僞傊偺僼僃僢僠偱偼側偄偲偄偆偙偲丅
側偤悇應偐偲偄偆偲丄僼傽儈僐儞偺CPU偼僇僗僞儉昳側偺偱丄
堦斒偺6502偵偁傞SYNC怣崋僺儞乮柦椷僼僃僢僠偺偲偒偵Hi偵側傞乯偑側偄偐傜丅
偙傟偵傛傝NOP偺応崌丄柦椷僼僃僢僠偼僆乕僶乕儔僢僾偟偰偄側偄偲峫偊傜傟傞丅
丂僆乕僶乕儔僢僾偵偮偄偰偼懠偵傕墘嶼偲柦椷僼僃僢僠傪僆乕僶乕儔僢僾偡傞偙偲偱丄 幚峴僋儘僢僋傪2僋儘僢僋偐傜1僋儘僢僋偵抁弅偱偒偦偆側柦椷偑尒傜傟傞丅 偟偐偟昁偢戞堦僆儁儔儞僪傪僼僃僢僠偡傞巇條傪桪愭偟偨偨傔偐 乮偙傟偵傛偭偰夞楬婯柾偑嶍尭偝傟偨乯丄 6502偵偼1僋儘僢僋偺柦椷偼懚嵼偟側偄丅
丂梋択偩偑丄6502偺尦偲側偭偨偲偄傢傟傞6800偺僽儔儞僠柦椷偼4僋儘僢僋偩偑丄 6502偼2乣4僋儘僢僋偲抁弅偝傟偰偄傞丅 偙傟偼傾僪儗僗壛嶼偵偍偄偰忋埵僶僀僩傊偺寘忋偘偑敪惗偟側偄応崌偵桳岠偱偁傝丄 僷僀僾儔僀儞偲偼娭學側偄偑僋儘僢僋嶍尭偵婑梌偟偰偄傞丅
丂偄偢傟偵偟偰傕丄6502偼柦椷僷僀僾儔僀儞傪帩偭偰偄側偄偲峫偊傞丅 6502偼僷僀僾儔僀儞偺柌傪尒傞丅屌掕挿柦椷偠傖側偄偗偳壜擻側偺偐丠
丵
仴 BCD(10恑)墘嶼偑柍偄儚働丠
丂僼傽儈僐儞偵巊梡偝傟偰偄傞僇僗僞儉僠僢僾RP2A03(6502+僒僂儞僪夞楬)偼BCD墘嶼(2恑壔10恑昞尰)偑巊梡偱偒側偄偲偄偆偺偼桳柤側榖丅 揰悢昞帵側偳偱BCD偑偁傟偽昞帵儖乕僠儞偑娙扨偵側傞傛偆側婥偑偡傞偑丅 偱偼側偤BCD墘嶼偑柍偄偺偐丄埲壓偺傛偆側棟桼傪峫偊偰傒偨丅
- 夞楬婯柾傪嶍尭偡傞偨傔丠
ALU傪FPGA偵幚憰偟偨偲偒偺応崌偩偑丄 BCD夞楬傪嶍彍偡傞偲120仺96LCs偵尭傝丄僋儕僥傿僇儖僷僗傕24仺20ns偵尭偭偨丅 BCD偼堄奜偲儕僜乕僗傪徚旓偡傞傜偟偄丅 - 僇僗僞儉LSI偺尨壙傪梷偊傞偨傔丠
BCD夞楬晹暘偑僆僾僔儑儞埖偄偱丄偱偒傞偩偗尨壙傪梷偊傞偨傔偵偙傟傪奜偟偨丄偲偄偆悇應丅 - 崅惛搙側墘嶼傪憐掕偟偰偄側偄丠
壢妛媄弍寁嶼傗嬥梈僔僗僥儉側偳偱偼BCD偑廳梫側応崌偑偁傞丅 2恑墘嶼偱偼丄彫悢揰埲壓偺娵傔岆嵎偑敪惗偟偰偟傑偆偨傔偩丅 僼傽儈僐儞偱偼偦偙傑偱偺惛搙偼晄梫偩偭偨丅 - 彨棃揑偵BCD夞楬偼嶍彍懳徾偵側傝偦偆偩偭偨丠
HDL偵傛傞愝寁側傜娙扨偵夞楬傪嶍彍偱偒傞偑丄摉帪偼巻偱儗僀傾僂僩愝寁偟偰偄偨傜偟偄丅 屻乆偵僾儘僙僗偑岦忋偟偰丄僐僗僩傪梷偊傞偨傔偵BCD偑嶍彍懳徾偵側傞側傜丄 弶傔偐傜嶍彍偟偰偍偙偆丄偲偄偆悇應丅 偙傟偵傛傝BCD傪巊梡偟偨僾儘僌儔儉偼嶌傜傟側偐偭偨丅 - 幚偼晄嬶崌丠
BCD夞楬偼懚嵼偡傞偑D僼儔僌偑愙懕偝傟偰偄側偄丅
丂幚嵺偺偲偙傠Richo偺奐敪幰偵暦偔偺偑堦斣側傢偗偩偗偳丅
丂[RP2A03G偺僠僢僾夋憸]傪尒傞偲丄 6502晹暘偺儗僀傾僂僩偼MOS TECHNOLOGY幮偺儗僀傾僂僩偲婎杮摨偠偵尒偊傞偨傔丄BCD墘嶼夞楬傕偦偺傑傑偺傛偆偩丅 [Chip Images : RP2A03] 偵偼乽偄偔偮偐偺儗僕僗僞偑堄恾揑偵嶍彍偝傟偰偄傞傛偆偩乿偲偄偆傛偆側偙偲偑彂偄偰偁傞丅 BCD墘嶼夞楬帺懱偼懚嵼偡傞偑丄D僼儔僌偑愙懕偝傟偰偄側偄偲偄偆梊憐偑偄偪偽傫嬤偄偺偐傕丅 側偤愙懕偝傟偰偄側偄偺偐偼晄柧偩偑丄 摿嫋偵娭楢偡傞棟桼偱BCD墘嶼夞楬傪巊梡晄壜偵偣偞傞傪摼側偐偭偨偲偄偆偺偑桳椡丠 [Integrated circuit microprocessor with parallel binary adder having on-the-fly correction to provide decimal results]
丂偪側傒偵BCD夞楬偑搵嵹偝傟偰偄傞僆儕僕僫儖6502偲丄 CMOS斉偺奺幮65C02偱偼僋儘僢僋悢偑堎側傝丄 65C02偺応崌偼D僼儔僌偑僙僢僩偝傟偰偄傞偲偒亄1僋儘僢僋偲側傞丅 偙傟偼墘嶼寢壥偵傛傞僼儔僌妋掕傪師僋儘僢僋偵偟偰摦嶌廃攇悢傪忋偘傛偆偲偟偨傕偺偩偲巚傢傟傞丅
丵
仴 僋儘僢僋悢傪崌傢偣傛俀乮僼儗乕儉儗乕僩傕偹乯 2026/05/06
丂CPU偺僥僗僩僒儞僾儖偲偟偰 [cpu_timing_test.nes]偑偁傝丄 奺柦椷傾僪儗僢僔儞僌偵偍偗傞僒僀僋儖悢傪幚婡摨條偵嵞尰偱偒偰偄傞偐妋擣偱偒傞丅 偟偐偟摦偐偟偰傒傞偲乽BASIC TIMING WRONG乿偲尵傢傟偰偟傑偆乧丅 偳偆傗傜僥僗僩偱偼僒僀僋儖悢僇僂儞僩偺偨傔丄惓妋側NMI僞僀儈儞僌傕嵞尰偟偰偄傞昁梫偑偁傞傢偗偩丅
丂惓妋側NMI僞僀儈儞僌偺偨傔偵偼幚婡僼儗乕儉儗乕僩 60.0988 Hz 偺嵞尰偑昁梫偩偑丄
FPGA偺儀乕僗僋儘僢僋偲PLL偵傛偭偰偼惓妋偵嵞尰偱偒偢丄偁傞掱搙偺岆嵎偼峫椂偡傞昁梫偑偁傞丅
偦傟偵攝椂偝傟偰偄傞偨傔偐cpu_timing_test偱偼NMI娫憤僋儘僢僋悢偺偆偪侾儔僀儞暘傎偳偺岆嵎偼嫋梕偝傟偰偄傞傛偆偩丅
偝偰丄VGA偍傛傃DVI傊偺弌椡傪慜採偲偟偰僪僢僩僋儘僢僋偲丄V 262 x 2 = 524 line 偐傜嶼弌偡傞偲丄
V 524 line, H 793 dot = 60.1030 Hz乮岆嵎栺70ppm乯偑椙偝偦偆丅
偟偐偟丄尰忬偺PPU昤夋儘僕僢僋偱偼 H 794 dot暘偺帪娫偼昁梫丅
偙偺偨傔 V 524 line, H 794 dot = 60.0150 Hz乮岆嵎栺1,400ppm乯傪慖掕偟嫋梕岆嵎偵偼廂傑偭偨偑丄
惛搙偵娭偟偰偼崱屻偺壽戣偲偟傛偆丅
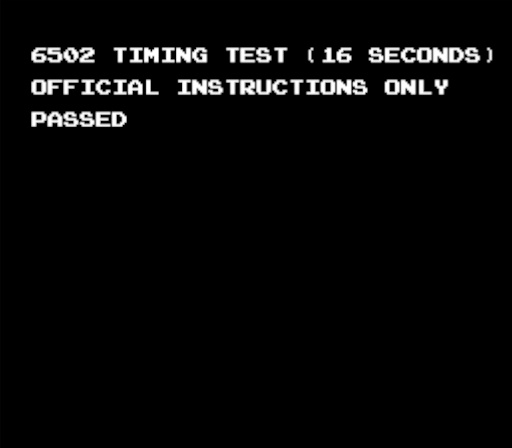
柦椷僞僀儈儞僌僥僗僩PASS両
丂儀乕僗偺僞僀儈儞僌偼崌傢偣偨偺偱丄奺柦椷偲偦傟傜傾僪儗僢僔儞僌偺僠僃僢僋偑恑傓丅
偦偟偰偁偭偨傛僞僀儈儞僌堘偄乧
LDA,LDX,LDY偱偺傾僽僜儕儏乕僩僀儞僨僢僋僗傗僀儞僟僀儗僋僩Y偱丄
僀儞僨僢僋僗壛嶼帪偺儁乕僕嫬奅傑偨偓偱1僒僀僋儖壛嶼偟偰偄偨偑丄
柍忦審偵1僒僀僋儖捛壛偡傞働乕僗偑偁傝偦偺晹暘傪廋惓丅
柍帠僞僀儈儞僌僥僗僩傪僷僗偱偒偨丅